AustinTek 1
From: http://www.austintek.com/LVS/LVS-HOWTO/HOWTO/LVS-HOWTO.filter_rules.html
LVS (Linux Virtal Server)
29. LVS: Running a firewall
on the director: Interaction between LVS and netfilter (iptables).
Note
May 2004: This chapter has been rewritten. Before the arrival of the Antefacto
patches, it was not possible to run arbitary iptables rules for ip_vs controlled
packets on a director. Hence you couldn't run a firewall on the director and we
told people to put their firewall on a separate box. Julian then took over
writing the code and now it is possible to run a firewall on the director. The
code is now called ipvs netfilter connection tracking module, ipvs_nfct and is
still beta, so keep us informed of how it works. In previous writeups, I
misunderstood how the code worked, and made some incorrect statements. Hopefully
this rewrite fixes the misinformation I propagated.
For one of many introductions to netfilter see The netfilter framework in
Linux 2.4 (http://gnumonks.org/~laforge/presentations/netfilter
-lk2000/netfilter.ps.gz).
According to Ratz (18 Apr 2006), NFCT causes a 20% throughput drop on a GbE
inbound service.
29.1. Start with no filter rules
Although this chapter is about applying iptables rules to directors, be
aware that you don't need filter rules to set up an LVS. Misconfiguring the
filter rules may cause strange effects. Make sure for testing that you can
turn your filter rules on and off. Here's a cautionary tale.
Sebastiaan Tesink maillist-lvs (at) virtualconcepts (dot) nl 14 Jul 2006
On one of our clusters we have problems with ipvs at the moment. Our cluster is
built with 2 front-end failover ipvs-nodes (managed with ldirectord), with 3
Apache back-end nodes, handling both http as well as https. So all the traffic
on a virtual ip on port 80 or 443 of the front-end servers is redirected to the
backend webservers.
Two weeks ago, we were running a 2.6.8-2-686-smp Debian stable kernel,
containing ipvs 1.2.0. We experienced weekly (6 to 8 days) server crashes, which
caused the machines to hang completely without any log-information whatsoever.
These crashes seemed to be related to IPVS, since all our servers have the
exact same configuration, except for the additional ipvs -modules on the
front-end servers. Additionally, the same Dell SC1425 servers are used for all
servers.
For this reason we upgraded our kernel to 2.6.16-2-686-smp (containing ipvs
1.2.1) on Debian stable, which we installed from backports
(http://www.backports.org). There aren't any crashes on these machines anymore.
However, there are two strange things we noticed since this upgrade. First of
all, the number of active connections has increased dramatically, from 1,200
with a 2.6.8-2-686-smp kernel, to well over 30,000 with the new kernel. We are
handling the same amount of traffic.
# ipvsadm -L
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP XXX.net wlc persistent 120
-> apache1:https Route 10 2 0
-> apache2:https Route 10 25 0
-> apache3:https Route 10 14 0
TCP XXX.net wlc persistent 120
-> apache1:www Route 10 10928 13
-> apache2:www Route 10 11433 6
-> apache3:www Route 10 11764 10
We are using the following IPVS modules: ip_vs ip_vs_rr ip_vs_wlc
Secondly, Internet Explorer users are experiencing problems exactly since
the upgrade to the new ipvs version. With Internet Explorer, an enormous
amount of tcp-connections is opened when visiting a website. Users are
experiencing high loads on their local machines, and crashing Internet
Explorers. With any version of FireFox this is working fine by the way.
Nevertheless, this started exactly since our IPVS upgrade.
Note
Note IE/IIS breaks tcpip rules to make loading fast (see What makes IE so
fast http://grotto11.com/blog/slash.html?+1039831658
Sebastiaan Tesink sebas (at) virtualconcepts (dot) nl 19 Jun 2007
The solution to this problem was relatively easy, but we only discovered it
recently. Basically, this problem was caused by the firewall, which
contained "state checks". We used to have the following iptable rule:
iptables -A INPUT -m state --state NEW -p tcp --dport 80 -j ACCEPT
While using IP_VS, this caused connections to be denied by the firewall.
Therefore we changed this to:
iptables -A INPUT -p tcp --dport 80 -j ACCEPT
which leads to a more balanced view on the number of active versus inactive
connections in the load balancer. Hopefully this is some useful information
to get your documentation even better.
29.2. Introduction
For 2.4.x kernels (and beyond), LVS was rewritten as a netfilter module,
rather than as a piece of stand-alone kernel code. Despite initial
expectations by Rusty Russel that LVS could be written as a loadable
netfilter module, it turned out not to be possible to write LVS completely
within the netfilter framework. As well, there was a minor performance
penalty (presumably in latency) for LVS as a netfilter module compared to
the original version. This penalty has mostly gone with rewrites of the
code.
The problem was in connection tracking, which among other things allows the
machine to determine if a packet belongs to a RELATED or ESTABLISHED
connection. As well connection tracking helps with multiport protocols like
FTP-NAT. The ip_vs controlled packets take a different path through the
routing code than do non-LVS packets. The netfilter connection tracking
doesn't know about the ip_vs controlled packets. Even if it did know about
them, netfilter conntrack was considered too slow to use for LVS.
For LVS-DR and LVS-Tun, where the reply packets do not go through the director,
netfilter is not able to connection tracking on these packets at all. The
Antefacto patches were written to allow connection tracking of ip_vs controlled
packets for LVS-NAT. Connection tracking for ip_vs with LVS -DR or LVS-Tun was
not attempted. The ipvs_nfct code now allows conntrack for LVS-DR and LVS-Tun.
Julian
You can (and always have been able to) use firewall rules that match by device,
proto, port or IP, without using ipvs netfilter connection tracking module,
ipvs_nfct.
Julian 16 Mar 2007
The NFCT patch is not a way to use iptables NAT rules, it just provides
iptables -m state support for IPVS packets.
snat_reroute is only for IPVS packets. I just added some information in
HOWTO.txt (http://www.ssi.bg/~ja/nfct/HOWTO.txt). SNAT: translate source
address. Reroute: call output routing for 2nd time (saddr=VIP), first was
the normal input routing for saddr=RIP.
29.3. Netfilter hooks and LVS:
the path/route of an ip_vs controlled packet
Horms horms (at) verge (dot) net (dot) au 19 May 2004
here is my understanding of the way that the Netfilter Hooks and LVS fit
together.
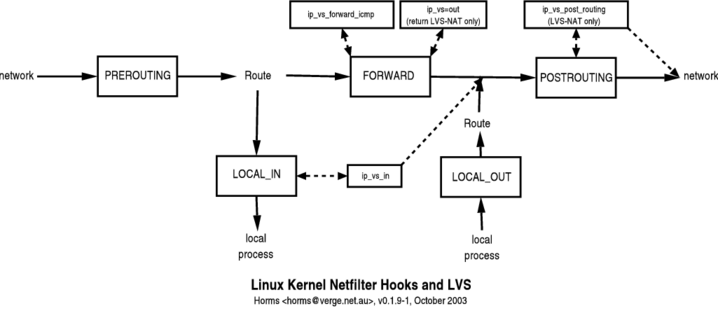 Figure 1. Interaction of LVS with Netfilter interactions between netfilter and
LVS.
The location of LVS hooks into the netfilter framework on the director. Packets
travel from left to right. A packet coming from the client enters on the left
and exits on the right heading for the realserver. A reply from the realserver
(in the case of LVS-NAT) enters on the left and exits on the right heading for
the client. For normal LVS-DR and LVS-Tun operation (see the martian
modification), reply packets do not go through the director.
Figure 1. Interaction of LVS with Netfilter interactions between netfilter and
LVS.
The location of LVS hooks into the netfilter framework on the director. Packets
travel from left to right. A packet coming from the client enters on the left
and exits on the right heading for the realserver. A reply from the realserver
(in the case of LVS-NAT) enters on the left and exits on the right heading for
the client. For normal LVS-DR and LVS-Tun operation (see the martian
modification), reply packets do not go through the director.
- for incoming packets the path is:
PREROUTING -> LOCAL_IN -> POSTROUTING
- for outgoing packets (only LVS-NAT):
PREROUTING -> FORWARD -> POSTROUTING
- for incoming ICMP:
PREROUTING -> FORWARD -> POSTROUTING
When the director receives a packet, it goes through PREROUTING where Routing
decides that the packet is local (usually because of the presence of the VIP on
a local interface). The packet is then sent to LOCAL_IN. On the inbound
direction, LVS hooks into LOCAL_IN. Modules register with a priority, the lowest
priority getting to look at the packets first. LVS registers itself with a
higher priority than iptables rules, and thus iptables will get the packet first
and then LVS.
Mike McLean mikem (at) redhat (dot) com 21 Oct 2002
On the director, filter rules intercept packets before ip_vs sees them,
otherwise firewall mark (fwmark) would not work
If LVS gets the packet and decides to forward it to a realserver, the
packet
then magically ends up in the POSTROUTING chain.
LVS does not look for ingress packets in the FORWARD chain. The only time
that the FORWARD chain comes into play with LVS is for return packets from
realservers when LVS-NAT is in use. This is where the packets get unNATed.
Again LVS gets the packets after any iptables FORWARDing rules.
ip_vs_in attaches to the LOCAL_IN hook. For a packet to arrive at LOCAL_IN,
the dst_addr has to be an IP on a local interface (any interface e.g.
eth0).
The result of this requirement (that dst_addr is an IP on a local
interface)
is that you still need the VIP on the director, when accepting packets for
LVS by VIP-less methods like fwmark or transparent proxy. (It would be nice
to remove the requirement for this otherwise non-functional VIP.)
There are ways around the requirement for a local IP, but they may create
other problems as well.
- move ip_vs_in from the LOCAL_IN hook to the PREROUTING hook. I tried
that briefly once and it seemed to work.
- play with routing rules to deliver the packet locally e.g. VIP-less
routing info or Matt wrote:
http://marc.theaimsgroup.com/?l=linux-virtual-server&m=104265930914084&w=2
ip rule add prio 100 fwmark 1 table 100
ip route add local 0/0 dev lo table 100
or perhaps
VIP=10.0.0.1/32
ip rule add prio 100 to $VIP table 100
ip route add local 0/0 dev lo table 100
But I haven't tested either much. There is an oblique reference to this
on http://www.linuxvirtualserver.org/docs/arp.html.
If packets for the VIP (on say eth0) started arriving on another interface
(say eth1) due to dynamic routing, then LVS wouldn't care - the packet still
arrives at LOCAL-IN. rp_filter would probably need to be disabled, and
perhaps a few other routing tweaks, but fundamentally if the director could
route the traffic (i.e. get the packets), then LVS could load balance it.
29.4. how to filter with netfilter
Note
netfilter has several families of rules, e.g. NAT and filter. The filter
rules filter, but do not alter, packets. Not all iptables commands are
filter rules.
For some background on filtering with netfilter, see the Linux netfilter
Hacking HOWTO (http://www.netfilter.org/documentation/HOWTO/netfilter
-hacking-HOWTO.html). Although iptables rules can be applied at any chain,
the filter rules are only applied at the LOCAL_IN, FORWARD and LOCAL_OUT
(see Packet Selection: IP Tables http://www.netfilte
r.org/documentation/HOWTO/netfilter-hacking-HOWTO-3.html#ss3.2).
Horms: LOCAL_IN and LOCAL_OUT in the kernel correspond, more or less, to
INPUT and OUTPUT in iptables.
Since any packet only traverses one of these three chains, for any packet
then, there is one and only one place to filter it. This is a change from
ipchains, when you could filter a packet in several chains. You can't filter
in the other chains even if you want to.
Julian
by design you can filter only in these chains because iptable_filter
registers only there:
+ Netfilter hooks
+ LOCAL_IN Tables with different priority
+ filter
+ Chains
- INPUT (and other chains used with -j CHAIN_NAME)
+ mangle
+ Chains
- INPUT
we have hooks (places in the kernel stack) where each table module attaches
its chains with rules for packet matching. It is a tree with multiple levels
of lists. Filtering never worked in the other chains. Table "filter" has
only chains INPUT, FORWARD and OUTPUT, each used in the corresponding hook.
Horms
You can see how many packets and bytes a rule is effecting by running
iptables -t nat -L -v -n
iptables -L -v -n
Here's a diagram from Linux Firewalls using iptables
(http://www.linuxhomenetworking.com/wiki/index.php/Q
uick_HOWTO_:_Ch14_:_Linux_Firewalls_Using_iptables), with LOCAL_IN
relabelled as INPUT etc.
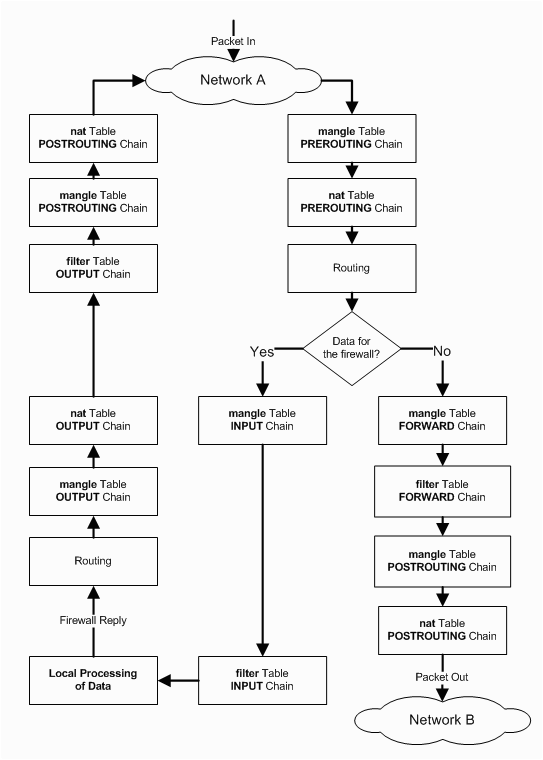 Figure 2. Diagram from "Linux Firewalls Using iptables"
Diagram from Linux Firewalls using iptables
Figure 2. Diagram from "Linux Firewalls Using iptables"
Diagram from Linux Firewalls using iptables
29.5. ipvs_nfct, netfilter connection tracking for ipvs
For some information on netfilter connection tracking (nfct) see Linux
netfilter Hacking HOWTO (http://www.netfilter.org/do
cumentation/HOWTO/netfilter-hacking-HOWTO.html).
May 2004: Because ipvs changes the path of LVS controlled packets, netfilter
is not able to connection track them. For LVS-NAT (and for LVS-DR/Tun when
using the forward_shared flag for the martian modification), packets in both
directions go through the director, so it is possible to write replacement
conntrack code (e.g. Antefacto patches).
For LVS-DR, LVS-Tun, the return packets go directly from the realserver to
the client and do not go through the director. You can infer the state of
the connection using the same mechanism (timeouts) by which the LVS-DR/LVS
-Tun director has always made decisions on the state of the connection
(where connections are listed as ActiveConn and InActConn by ipvsadm). There
ip_vs assumes that connections are setup and terminated in a normal manner.
The first implementations of ipvs used the standard ivp4 timeouts to declare
a state transition. More recent implementations allow for a private set of
timeout values for the ip_vs controlled connections (see tcp timeouts and
the private copies of these timeouts for ipvs).
Joe - 29 Jan 2003
There were some incompatibilities between LVS and netfilter when running
a director and firewall on the same box with 2.4.x?
Julian
Yes, LVS and Netfilter use their own (separate) connection tracking
implementations. The situation hasn't changed since I explained it January
2002. If we are going to fix this, then changes in Netfilter are required
too, mostly in the routing usage. LVS has some requirements for the
connection state which are not present in netfilter. I don't think it is
good to move LVS to Netfilter conntracking. And I still don't have enough
time to think about such big changes for LVS.
May 2004: Julian has written the ipvs_nfct module, which among other things,
fakes the connection tracking for LVS-DR and LVS-Tun.
Julian's ipvs_nfct code for LVS for 2.4 and 2.6 kernels are on his Netfilter
Connection Tracking Support page (http://www.ssi.bg/~ja/nfct/). This page is
accessed from Julian's software page (http://www.ssi.bg/~ja/) through "Linux
IPVS tools and extensions: IPVS Netfilter connection tracking support").
Because of the small demand for this functionality, this code is one of
Julian's lower priority projects.
Julian's HOWTO that comes with his patches states that the return packets
have to go through the director. In fact the patch works for all LVS
forwarding methods, but really is only useful for LVS's in which the replies
return through the director.
Julian
I've uploaded the 2.6 version of the NFCT patches, but they aren't tested.
ipvs_nfct matchs conntrack state for IPVS connections, e.g. NEW,
ESTABLISHED, RELATED.
Note
Julian doesn't have a setup to test most of his code. Any untested code from
Julian that I've tried has worked first time.
The only problem is with the netfilter's non-official tcp window tracking
patch (which I haven't tested) that only works for NAT (I suspect). Maybe
some of the checks done in the tcp window tracking patch require a
bidirectional stream, so possibly it doesn't work for the unidirectional LVS
-DR or LVS-TUN connections, i.e. when the director doesn't see the reply
packets. In all other cases (LVS-NAT or bidirectional DR/TUN with
forward_shared=1)
For LVS-NAT, ip_vs forwards packets in both directions in the director. For
LVS-DR and LVS-TUN the replies are visible to the Netfilter firewall on the
director if is the default gw for the realservers (for LVS-DR this requires
the julians_martian_modification or forward_shared patch). Even if these
reply packets are not part of the ipvs stream, they are forwarded, since
forward_shared=1. For the Netfilter firewall, there is no difference in the
forwarding method. In all cases the incoming traffic is handled in LOCAL_IN
and the replies in FORWARD.
IPVS always knows the conn state (NEW/RELATED/ESTABLISHED), it is simply
exported to the netfilter conntracking.
The patch works for cases when the replies don't go through the director,
but in this case it is not very useful. The main purpose of the patch is to
match reply packets. For the request packets, the conntrack entry is
confirmed, which can speedup the packet handling (I hope). IPVS without NFCT
drops the conntrack entry for each packet and allocates the conntrack entry
again for the next packet.
With ipvs_nfct, each skb comes with skb->nfct attached. ipvs-nfct preserves
this NFCT struct, while the default IPVS drops it on skb free.
Joe
Your NFCT HOWTO with date 10 Apr 2004 (but internal date Sep 2003) says
that NFCT works for LVS-NAT and forward shared LVS-DR etc, but doesn't say
anything about LVS-DR, LVS-Tun
non-NAT methods if forward_shared flag is used
I assume NFCT provides perfect conntrack for LVS when the replies go
through the director and hence you can you use all iptables commands (eg
ESTABLISHED). I assume RELATED will need helpers.
Yes, I'm just not sure for FTP for DR/TUN because ip_vs_ftp is not used (for
LVS-DR, ftp requires persistence). IIRC, without creating NF expectations we
can not expect to match FTP-DATA as RELATED.
For LVS-DR etc, your reply above seems to indicate that NFCT provides
conntrack for LVS-DR too, however your NFCT HOWTO doesn't mention it.
Yes, it does not mention for any restrictions but the source has '- support
for all forwarding methods, not only NAT'. It is still beta software. As yet
there hasn't been a lot of interest in the code.
Is it OK to have a firewall on the director yet?
Yes, for simple ipchains-like rules. I can't be sure for more advanced
filtering rules that play with conntrack specific data but if you use only
device names, IPs, protos and ports it should work. ipvs works perfectly
with netfilter as far as iptables filter rules are concerned.
can the LVS director now (with ipvs_nfct) can have any iptables command
run on it, as if it were a regular linux router? Can I now expect to run any
iptables command on an ipvs virtual service stream and have it work like on
a normal linux box with an normal tcp/udp stream?
Maybe not because the IPVS packets do not use the same path through the
network stack as other non-IPVS packets. I can not guarantee complete
compatibility e.g you can do very wrong things with using some NAT rules,
for example, DNAT. ipvs_nfct when added to ipvs gives you the ability to use
-m state and nothing more. Now we can use -m state, with plain IPVS you can
not use -m state.
what doesn't work with LVS-DR/Tun?
We support -m state for DR and TUN too. The only thing that doesn't work for
DR and TUN is FTP-DATA.
Stephane Klein 26 Aug 2004
I installed your ipvs-nfct-2.4.26-1.diff patch, I enabled the
CONFIG_IP_VS_NFCT and recompiled the kernel. Here are my rules to enable
http service:
$IPTABLES -A INPUT -i eth1 -p tcp -m multiport -d $VIP --destination
-port 80,21 -m state --state NEW -j RULE_2
$IPTABLES -A RULE_2 -j LOG --log-level info --log-prefix "RULE 2 -- >
ACCEPT"
$IPTABLES -A RULE_2 -j ACCEPT
$IPTABLES -A FORWARD -p tcp -m state --state R,E -j ACCEPT
Julian
All out->in traffic passes INPUT (not FORWARD as in netfilter), you can not
allow only NEW packets. FORWARD is passed only for in->out traffic for NAT.
Some iptables examples can be found at the NFCT page
(http://www.ssi.bg/~ja/nfct/"). You can also read about the netfilter hooks
LVS uses here: my LVS page (http://www.ssi.bg/~ja/LVS.txt).
"Vince W." listacct1 (at) lvwnet (dot) com 12 Feb 2005
How I successfully compiled 2.6.9 and .10 FC3 kernels withip_vs_nfct patch
and GCC 3.4.2
As a followup of sorts to my previous posts, "Error building 2.6.10 kernel
with ip_vs_nfct patch - does anyone else get this?", I figured out what the
problem was, and with some advice from Julian Anastasov, was successful
getting kernels compiled with the ip_vs_nfct patch. This was the error
message I would get previously, at the modules stage of the kernel build:
CC [M] net/ipv4/ipvs/ip_vs_proto_ah.o
CC [M] net/ipv4/ipvs/ip_vs_nfct.o
net/ipv4/ipvs/ip_vs_nfct.c: In function `ip_vs_nfct_conn_drop':
include/linux/netfilter_ipv4/ip_conntrack.h:248: sorry, unimplemented:
inlining failed in call to 'ip_conntrack_put': function body not available
net/ipv4/ipvs/ip_vs_nfct.c:385: sorry, unimplemented: called from here
make[3]: *** [net/ipv4/ipvs/ip_vs_nfct.o] Error 1
make[2]: *** [net/ipv4/ipvs] Error 2
The system in question is Fedora Core 3, which sports version 3.4.2 of the
GNU C compiler (and everything in the release is built with it). The kernel
source I was using is the kernel-2.6.10-1.741_FC3.src.rpm. I had added the
ip_vs_nfct and nat patches to the kernel build spec file, inserted the
"CONFIG_IP_VS_NFCT=y" kernel config option line between the
"CONFIG_IP_VS_FTP=m" and "CONFIG_IPV6=m" lines of each kernel arch/type
*.config file, and built the kernel.
As it turns out, others have seen problems compiling code which contain
external inline functions with GCC 3.4.2, not just people trying to use
ip_vs_nfct. I found one such instance where the user documented that by
removing "inline" from the function declaration, they were able to compile
successfully.
Since ip_conntrack_put is declared and exported as an inline-type function
in include/linux/netfilter_ipv4/ip_conntrack.h, this seems to cause a
problem for ip_vs_nfct making use of the function. I asked Julian what he
thought about this idea, and he suggested that "inline" may need to be
removed from ip_conntrack_put's declaration in net/i
pv4/netfilter/ip_conntrack_core.c also, since this is where the function is
exported. Armed with this idea, I modified both ip_conntrack.h and
ip_conntrack_core.c to remove "inline" from the function, and created a
patch which I then added to the .spec and kernel build.
The kernel compiled successfully and ran. My firewall script worked, and
ip_vs_nfct did its job. Unfortunately, I discovered several uptime hours
later when the box kernel panicked that there is a known spinlock problem in
the 2.6.10 kernel - somewhere in the filesystem/block device drivers code. I
say known because comments exist in later iterations of the 2.6.10 kernel
spec changelog which indicate that steps were taken to increase the
verbosity of output when this specific kernel panic occurs. I do not know if
it is an issue with the upstream 2.6.10 sources or not, but at least I knew
it wasn't because of ip_vs_nfct.
At any rate, I have been successful building 2.6.9 FC3 kernels with Julian's
2.6.9 ip_vs_nfct patches, and not seeing the spinlock "not syncing" kernel
panics I saw building with any Fedora Core 3 2.6.10 kernel .src.rpm sources
I tried building with. It's been up for 3 days now on the box running this
kernel, and it is functioning exactly as desired. ...which also means it's
gonna be time to update my keepalived Stateful Firewall/LVS Director HOW-TO
document from 2003 (http://www.lvwnet.com/vince/linux/Keepalived-LVS-NAT
-Director-ProxyArp-Firewall-HOWTO.html) soon...
Specifically, I used the 2.6.9-1.681_FC3 .src.rpm file, including Julian's
two patches (ip_vs_nfct and also the nat patch) and the one shown below to
remove "inline" from the ip_conntrack_put function.
If anyone else is interested in building kernels using Julian's patches and
you have GCC 3.4.2 (or newer, I'm sure...) you may be interested in this
small patch to remove "inline" from ip_conntrack.h and ip_conntrack_core.c.
I'll attach it to this post, and also post the text of it here:
diff -urN ../linux-2.6.10/include/linux/netfilter_ipv4/ip_conntrack.h
./include/linux/netfilter_ipv4/ip_conntrack.h
---
../linux-2.6.10/include/linux/netfilter_ipv4/ip_conntrack.h 2004-12-24
16:35:28.000000000 -0500
+++ ./include/linux/netfilter_ipv4/ip_conntrack.h 2005-02-07
06:48:57.260570933 -0500
@@ -245,7 +245,9 @@
}
/* decrement reference count on a conntrack */
-extern inline void ip_conntrack_put(struct ip_conntrack *ct);
+/* vince: try this without inline:
+extern inline void ip_conntrack_put(struct ip_conntrack *ct); */
+extern void ip_conntrack_put(struct ip_conntrack *ct);
/* find unconfirmed expectation based on tuple */
struct ip_conntrack_expect *
diff -urN ../linux-2.6.10/net/ipv4/netfilter/ip_conntrack_core.c
./net/ipv4/netfilter/ip_conntrack_core.c
--- ../linux-2.6.10/net/ipv4/netfilter/ip_conntrack_core.c 2004-12-24
16:33:47.000000000 -0500
+++ ./net/ipv4/netfilter/ip_conntrack_core.c 2005-02-07
06:48:16.702522768 -0500
@@ -77,7 +77,9 @@
DEFINE_PER_CPU(struct ip_conntrack_stat, ip_conntrack_stat);
-inline void
+/* vince: try this without inline:
+inline void */
+void
ip_conntrack_put(struct ip_conntrack *ct)
{
IP_NF_ASSERT(ct);
If anyone else cares to comment on whether removing "inline" from
either/both of these places is good/bad, or what performance impact this may
have, please do tell. But it is working well for me so far.
--Boundary_(ID_Kepw1VtyitIN0uRSqVWEDA)
Content-type: text/plain; name="linux-2.6.10-ip_conntrack_put-no
-inline.diff"
Content-disposition: inline;
filename="linux-2.6.10-ip_conntrack_put-no-inline.diff"
Content-transfer-encoding: 7bit
diff -urN ../linux-2.6.10/include/linux/netfilter_ipv4/ip_conntrack.h
./include/linux/netfilter_ipv4/ip_conntrack.h
--- ../linux-2.6.10/include/linux/netfilter_ipv4/ip_conntrack.h 2004-12-24
16:35:28.000000000 -0500
+++ ./include/linux/netfilter_ipv4/ip_conntrack.h 2005-02-07
06:48:57.260570933 -0500
@@ -245,7 +245,9 @@
}
/* decrement reference count on a conntrack */
-extern inline void ip_conntrack_put(struct ip_conntrack *ct);
+/* vince: try this without inline:
+extern inline void ip_conntrack_put(struct ip_conntrack *ct); */
+extern void ip_conntrack_put(struct ip_conntrack *ct);
/* find unconfirmed expectation based on tuple */
struct ip_conntrack_expect *
diff -urN ../linux-2.6.10/net/ipv4/netfilter/ip_conntrack_core.c
./net/ipv4/netfilter/ip_conntrack_core.c
--- ../linux-2.6.10/net/ipv4/netfilter/ip_conntrack_core.c 2004-12-24
16:33:47.000000000 -0500
+++ ./net/ipv4/netfilter/ip_conntrack_core.c 2005-02-07 06:48:16.702522768
-0500
@@ -77,7 +77,9 @@
DEFINE_PER_CPU(struct ip_conntrack_stat, ip_conntrack_stat);
-inline void
+/* vince: try this without inline:
+inline void */
+void
ip_conntrack_put(struct ip_conntrack *ct)
{
IP_NF_ASSERT(ct);
29.6. LVS-NAT netfilter conntrack example with ftp
Julian Anastasov ja (at) ssi (dot) bg 19 May 2004
For users of ipvs-nfct I would recommend the following rules. The example is
for ftp by LVS-NAT to VIP=192.168.1.100. Access to all other ports on the VIP is denied.
# turn on conntrack and load helper modules
echo 1 > /proc/sys/net/ipv4/vs/conntrack
# module to correctly support connection expectations for FTP-DATA
modprobe ip_conntrack_ftp
# module to detect ports used for FTP-DATA
# (May 2004, has a kernel bug which hasn't been fixed)
# `modprobe ip_nat_ftp` is optional and ip_nat_ftp needs a fix:
# http://marc.theaimsgroup.com/?l=linux-netdev&m=108220842129842&w=2
# if ip_nat_ftp is used together with ipvs_nfct for FTP NAT.
modprobe ip_nat_ftp
# Restrict LOCAL_IN access
# accept packets to dport 21 and related and established connections.
# the related connections are determined by the ftp helper module
# drop all other packets
iptables -A INPUT -p tcp -d 192.168.1.100 --dport 21 -j ACCEPT
iptables -A INPUT -p tcp -d 192.168.1.100 -m state --state
RELATED,ESTABLISHED - j ACCEPT
iptables -A INPUT -p tcp -d 192.168.1.100 -j DROP
# Restrict FORWARD access
# accept only related, established. drop all others
iptables -A FORWARD -m state --state RELATED,ESTABLISHED -j ACCEPT
iptables -A FORWARD -j DROP
Without NFCT support it is difficult to filter in INPUT for FTP-DATA packets
but for http/https where the VPORT is known it is not difficult. The same
difficulties are IN FORWARD for the NAT replies. This is where ipvs-nfct
wins - you have only a small number of rules.
Traffic to the VIP is first filtered by iptables in INPUT and then scheduled
from IPVS. IPVS in 2.6 causes the scheduled out->in packets (after any LVS
-NAT translations) to appear in the LOCAL_OUT hook where they can be
filtered again.
IPVS works always after the filter rules. It is easy when you know the ports
but for FTP-DATA it is not possible, you have to specify input devices and
IPs for which you grant access for forwarding. You overcome such problems
with ipvs-nfct.
Ratz 03 Aug 2004
LVS-NAT with the NFCT patch will work for 2.4.x and 2.6.x kernels regarding
filtering, if you don't use fwmark
LVS-DR will most probably not work with 2.6.8 and above kernels regarding
filtering since the tcp window tracking patch has been merged to the vanilla
tree; however there is a relaxation sysctl that could revert the strict TCP
window and sequence number checking to the loosly-knitted one (aka: non
-existant) as previously found in vanilla Linux kernels.
29.7. tcpdump is LVS compatible
You can use tcpdump to debug your iptables rules on your running director.
tcpdump makes a copy of packets for its own use. tcpdump gets a copy of the
packets before netfilter (on the way in) and after netfilter (on the way
out). You should see all packets with tcpdump as if netfilter and LVS didn't
exist.
Joe 16 Mar 2001
I'm looking at packets after they've been accepted by TP and I'm using
(among other things) tcpdump.
Where in the netfilter chain does tcpdump look at incoming and outgoing
packets? When they are put on/received from the wire? After the INPUT,
before the OUTPUT chain...?
Julian
Before/after any netfilter chains. Such programs hook at packet level
before/after the IP stack just before/after the packet is received/must be
sent from/by the device. They work for other protocols. tcpdump is a packet
receiver just like the IP stack is in the network stack.
Note
If you are using twisted pair ethernet through a hub/switch, your NIC will
only see the packets to/from it. Thus tcpdump running on the director will
not see packets from the realserver to the client in LVS-DR. In the days
when people used coax for ethernet, all machines saw all packets on a segment.
29.8. Writing Filter Rules
If you're writing your own rules, start off with a quiet machine, log all
packets and then access one of the services. Write rules to accept the
packets you want and keep logging the rest. Try another service... Deny all
packets that you know aren't needed for your LVS.
You can probably accept all packets that have both src_addr and dst_addr in
the RIP network. As well machines might need access to outside services
(e.g. ntp, dns). Realservers that are part of 3-Tier LVS LVSs, will also
require rules to allow them to access outside services.
Joe (on changing from writing ipchains rules for ip_vs for 2.2, to writing
iptables rules for ip_vs for 2.4)
I see packets only in the INPUT and OUTPUT chains, but not in FORWARD or
in lvs_rules chains.
Ratz 21 May 2001
If you're dealing with netfilter, packets don't travel through all chains
anymore. Julian once wrote something about it:
packets coming from outside to the LVS do:
PRE_ROUTING -> LOCAL_IN(LVS in) -> POST_ROUTING
packets leaving the LVS travel:
PRE_ROUTING -> FORWARD(LVS out) -> POST_ROUTING
From the iptables howto:
COMPATIBILITY WITH IPCHAINS
This iptables is very similar to ipchains by Rusty Russell. The main
difference is that the chains INPUT and OUTPUT are only traversed for
packets coming into the local host and originating from the local host
respectively. Hence every packet only passes through one of the three
chains; previously a forwarded packet would pass through all three.
When writing filter rules (e.g. iptables), keep in mind
- write the rules in trees. If a packet has to traverse many rule tests
before it is accepted/rejected, then throughput will decrease. If many
packets traverse a rule set, then you should attempt to shorten the path
through the rules, possibly by breaking the rule set into several branches.
- Ratz has shown that you can have 200-500 rules in a branch before
throughput is affected (see pf-speed-test.pdf).
"K.W." kathiw (at) erols (dot) com
- can I run my ipchains firewall and LVS (piranha in this case) on the
same box? It would seem that I cannot, since ipchains can't understand
virtual interfaces such as eth0:1, etc.
Brian Edmonds bedmonds (at) antarcti (dot) ca 21 Feb 2001
I've not tried to use ipchains with alias interfaces, but I do use aliased
IP addresses in my incoming rulesets, and it works exactly as I would
expect
it to.
Julian
I'm not sure whether piranha already supports kernel 2.4, I have to
check it. ipchains does not understand interface aliases even in Linux 2.2.
Any setup that uses such aliases can be implemented without using them. I
don't know for routing restrictions that require using aliases.
I have a full ipchains firewall script, which works (includes port
forwarding), and a stripped-down ipchains script just for LVS, and they
each
work fine separately. When I merge them, I can't reach even just the
firewall box. As I mentioned, I suspect this is because of the virtual
interfaces required by LVS.
LVS does not require any (virtual) interfaces. LVS never checks the
devices nor any aliases. I'm not sure what is the port forwarding support
in
ipchains too. Is that the support provided from ipmasqadm: the portfw and
mfw modules? If yes, they are not implemented (yet). And this support is
not
related to ipchains at all. Some good features are still not ported from
Linux 2.2 to 2.4 including all these autofw useful things. But you can use
LVS in the places where use ipmasqadm portfw/mfw but not for the autofw
tricks. LVS can perfectly do the portfw job and even to extend it after the
NAT support: there are DR and TUN methods too.
Lorn Kay lorn_kay (at) hotmail (dot) com
I ran into a problem like this when adding firewall rules to my LVS
ipchains script. The problem I had was due to the order of the rules.
Remember that once a packet matches a rule in a chain it is kicked out
of the chain--it doesn't matter if it is an ACCEPT or REJECT rule(packets
may never get to your FWMARK rules, for example, if they do not come before
your ACCEPT and REJECT tests).
I am using virtual interfaces as well (eg, eth1:1) but, as Julian
points
out, I had no reason to apply ipchains rules to a specific virtual
interface
(even with an ipchains script that is several hundred lines long!)
unknown
FWMARKing does not have to be a part of an ACCEPT rule. If you have a
default DENY policy and then say:
/sbin/ipchains -A input -d $VIP -j ACCEPT
/sbin/ipchains -A input -d $VIP 80 -p tcp -m 3
/sbin/ipchains -A input -d $VIP 443 -p tcp -m 3
To maintain persistence between port 80 and 443 for https, for example,
the packets will match on the ACCEPT rule, get kicked out of the input chain
tests, and never get marked.
29.9. The Antefacto Netfilter Connection Tracking patches
The Problem: Because of the incompatibilities between netfilter and LVS, it
is not possible (in general) to have iptables firewall rules running on the
director (the firewall must be on a separate machine).
The first code (the Antefacto patches) were written by Ben North for 2.4
kernels, when he worked for (the now defunct) Antefacto. The code was then
(Jun 2003) taken over by Vinnie listacct1 (at) lvwnet (at) com and now (Apr
2004) being ported by Julian who calls them the "netfilter connection
tracking" (nfct) patches.
The original Antefacto patches allowed a firewall on directors in an LVS
where the packets from the realservers return through the director (LVS
-NAT,
and LVS-DR with the forward_shared flag when the director is the default gw
for the realservers). This restriction is required so that the director has
full information about the connection (in LVS-DR and LVS-Tun, the director
makes guesses about the state of the connection from timeout values).
Documentation for the Antefacto code is at setting up an LVS-NAT Director
(running keepalived) to function as a stateful firewall, which also happens
to use proxy-arp. The code is at Antefacto patch for 2.4.19/1.0.7 and
Antefacto patch for 2.4.20/1.0.8
29.9.1. The problem:director can't be firewall as well
John P. Looney john (at) antefacto (dot) com Apr 12, 2002
We modified ip_vs to get it to play nicely with iptables on the same
box, so you don't need a seperate firewall/vpn box.
The patches weren't accepted to the main branch, as the changes were
considered non-mainstream, and they were made from 0.8.2 version, which was
a little old then. Have a look at;
http://www.in-addr.de/pipermail/lvs-users/2002-January/004585.html
From memory (I didn't do the kernel work), the ip_vs connection tracking
tables and the netfilter connection tracking tables were not always in
synch. So, you couldn't statefully firewall an ip_vs service. There is a
readme included somewhere in that thread.
We've just done a product release. One of our aims is to reimplement
these changes in the 1.0.x branch, if someone hasn't already done so. When
that's done, we'll post those patches to the list also.
Here's the original posting from Ben North.
Ben North Software Engineer
a n t e f a c t o t: +353 1 8586008
www.antefacto.com f: +353 1 8586014
181 Parnell Street - Dublin 1 - Ireland
Note
Feb 2003: Antefacto no longer exists. You should be able to contact Ben at
ben (at) redfrontdoor (dot) org.
We've been working with the LVS code for the past while, and we wanted
to allow the use of Netfilter's connection-tracking ability with LVS-NAT
connections. There was a post on the mailing list a couple of weeks ago
asking about this, and my colleague Padraig Brady mentioned that we had
developed a solution.
I've now had time to clean up the patches, and I attach a README, and
two patch files. One is for the Linux kernel, and one is to the LVS code
itself. Any comments, get in touch. We have done a fair amount of testing
(overnight runs with many tens of thousands of connections), with no
problems.
Many thanks for the great piece of work. Hope the patches are useful
and
will be considered for inclusion in future releases of LVS. I notice that
1.0.0 is going to arrive soon; the attached patches might be better applied
to a Linux-kernel-style 1.1 "development" branch.
Vinnie listacct1 (at) lvwnet (dot) com 04 May 2003
Well I haven't tried to crash the firewall/Director or anything, but to sum
it up, the firewall box is doing its job now just as well as it was before
I
started dinking around with LVS/IPVS. It is letting traffic come IN that I
have IPVS virtual services for, and letting it be FORWARDED to the Real
Servers. It's not getting in the way of IPVS connections in progress, nor
does it appear to be letting traffic through which is NOT related to
connections already in progress.
Ratz
Guys, I hope you _do_ realize that not even netfilter has a properly
working connection tracking. Without the tcp-window-tracking patch,
netfilter allows you to send arbitrary packets through the stack. It's a
well-known fact and even the netfilter homepage at some point mentioned it.
Point taken. But that's not an IPVS or Antefacto problem.
I take it that you didn't do any tests of the patch or netfilter in
general with a packet generator (where you can modify every last bit of an
skb).
No, I can't say that I have. Perhaps you would be willing to put some of
that expertise you have to work?
And, to your interest, LVS _does_ have sort of connection state
tracking.
I am aware of that. But the point about all of this (and the reason that
the
folks who actually wrote the Antefacto patch did so) is that IPVS works
independently of netfilter's connection tracking. So Netfilter doesn't have
a CLUE about all those connections going on (or not going on) to IPVS-based
services and RealServers.
But if you want your LVS Director to also be your main firewall, that means
you have to be able to tell your firewall box, in ways that you can
communicate your wishes with iptables commands, what kind of traffic you
want to allow to go in/out of your LVS. But that's pretty hard to do since
IPVS unmodified doesn't bother to let netfilter in on the loop of what it's
doing.
The antefacto patch allows netfilter and IPVS to communicate about all that
traffic going through your LVS, so that at the iptables ruleset level, it
is
possible to write rules that work for your LVS.
If netfilter's connection tracking is broken, then it's broken -- IPVS,
Antefacto, or not.
29.9.2. the patches
Following patches, Copyright (C) 2001--2002 Antefacto Ltd, 181 Parnell St,
Dublin 1, Ireland, released under GPL, and then Ben's documentation on the patch.
First the patch to the kernel sources (http://www.austintek.com/WWW/LVS/LVS
-HOWTO/HOWTO/files/antefacto_kernel.diff)
And second, the patch to the LVS sources (http://www.austintek.com/LVS/LVS
-HOWTO/HOWTO/files/antefacto_lvs.diff) (made against 0.8.2 so may need some
clean-up).
29.9.3. Making LVS work with Netfilter's connection tracking
The two attached patches modify the kernel and the ipvs modules in such a
way that ipvs NAT connections are correctly tracked by the Netfilter
connection-tracking code. This means that firewalling rules can be put in
place to allow incoming connections to a virtual service, and then by
allowing ESTABLISHED and RELATED packets to pass the FORWARD chain, we
achieve stateful firewalling of these connections.
For example, if director 4.3.2.1 is offering a virtual service on TCP port
8899, we can do
iptables -A INPUT -p tcp -d 4.3.2.1 --dport 8899 -m state --state
NEW,ESTABLISHED,RELATED
iptables -A FORWARD -p tcp -m state --state ESTABLISHED,RELATED
and get the desired behaviour. Note that the second rule (the one in the
FORWARD chain) covers all virtual services offered by the same director, so
if another service is offered on port 9900, the complete set of rules
required would be
iptables -A INPUT -p tcp -d 4.3.2.1 --dport 8899 -m state --state
NEW,ESTABLISHED,RELATED
iptables -A INPUT -p tcp -d 4.3.2.1 --dport 9900 -m state --state
NEW,ESTABLISHED,RELATED
iptables -A FORWARD -p tcp -m state --state ESTABLISHED,RELATED
i.e., one rule in the INPUT chain is required per virtual service, but the
rule in the FORWARD chain covers all virtual services.
Patches required
- Patch to main kernel source
There is a small change required to the kernel patch. The stock kernel
patch which comes with the ip_vs distribution just adds a few
EXPORT_SYMBOL()s to ksyms.c. For the Netfilter connection-tracking
functionality, we need a bit more. The files affected, and reasons, are:
ip_conntrack_core.c: init_conntrack(): Mark even more clearly that the
newly-created connection-tracking entry is not in the hash tables. This
change isn't strictly necessary but makes assertion-checking easier.
ip_conntrack_standalone.c: Export the symbol __ip_conntrack_confirm().
I
didn't really like the idea of exporting a symbol starting with double
-underscore, but nothing too bad seems to have happened. The function seems
to take care of reference-counting, so I think we're OK here.
ip_nat_core.c: ip_nat_replace_in_hashes(): (new function) Exported
wrapper round replace_in_hashes() which deals with the locking on
ip_nat_lock.
ip_nat_standalone.c: Export the new ip_nat_replace_in_hashes()
function.
ip_nat.h: Declare the new ip_nat_replace_in_hashes() function.
More explanation below.
- Patch to ip_vs code
ip_vs_app.c: skb_replace(): Copy debugging information across to the
new
skb, if debugging is enabled. This is a separate issue to the main
connection-tracking patch, but was causing spurious warnings about which
hooks a skb had passed through.
ip_vs_conn.c: Include some netfilter header files. Declare a new
function ip_vs_deal_with_conntrack().
ip_vs_nat_xmit(): Code to make sure that Netfilter's connection
-tracking
entry is correct.
ip_vs_deal_with_conntrack(): (new function) The guts of the new
functionality. Changes the data inside the Netfilter connection-tracking
entry to match the actual packet flow.
ip_vs_core.c: route_me_harder(): (new function) Copied from
ip_nat_standalone.c. Code to re-make the routing decision for a packet,
treated as locally-generated.
ip_vs_out(): Separate from the connection-tracking code changes, don't
send ICMP unreachable messages. This has been discussed on the list
recently
and I think the consensus was that this change is OK. The sysctl method
would be better though, so ignore this bit.
Also call route_me_harder() to decide whether the outbound packet needs
to be routed differently now it is supposed to be coming from the director
machine itself.
ip_vs_in(): When checking if a packet might be trying to start a new
connection, check that it has SYN but not ACK. Previously, the only check
was that it had SYN set.
If there is a new connection being attempted, check for consistency
between Netfilter's connection-tracking table and LVS'. More explanation of
this bit below.
ip_vs_ftp.c: Include the Netfilter header files. Declare new function
ip_vs_ftp_expect_callback().
ip_vs_ftp_out(): Once we have noticed that a passive data-transfer
connection has been negotiated at application level, tell Netfilter to
expect this connection and so treat it as RELATED.
ip_vs_ftp_in(): Once we have noticed that an active data-transfer
connection has been negotiated at application level, tell Netfilter to
expect this connection and so treat it as RELATED.
ip_vs_ftp_expect_callback(): (new function) When the RELATED packet
arrives (for a data-transfer connection), update Netfilter's connection
-tracking entry for the connection.
29.9.3.1. General connections (i.e. not FTP)
Each entry in Netfilter's connection-tracking table has two tuples
describing source and destination addresses and ports. One of these tuples
is the ORIG tuple, and describes the addressing of packets travelling in
the
"original" direction, i.e., from the machine that initiated the connection
to the machine that responded. The other is the REPLY tuple, which describes
the addressing of packets travelling in the "reply" direction, i.e., from
the responding machine to the initiating machine. Normally, the REPLY tuple
is just the "inverse" of the ORIG tuple, i.e., has its source and
destination reversed. But for LVS connections, this is not the case. This is
what causes the problem when using the unmodified Netfilter code with IPVS
connections. Actually, it's one of the things that causes trouble.
The following is roughly what happens with the unmodified code for the start
of a TCP connection to a virtual service. Suppose we have
+--------+
| Client |
+--------+
(CIP) < Client's IP address
|
|
{ internet }
|
|
(VIP) < Virtual IP address
+----------+
| Director |
+----------+
(PIP) < (Director's Private IP address)
|
|
(RIP) < Real (server's) IP address
+-------------+
| Real server |
+-------------+
Then the client sends a packet to the VIP:VPORT; say
CIP:CPORT -> VIP:VPORT
Netfilter on the director makes a note of this packet, and sets up a
temporary connection-tracking entry with tuples as follows:
ORIG: CIP:CPORT -> VIP:VPORT
REPL: VIP:VPORT -> CIP:CPORT
(the "src-ip:src-port -> dest-ip:dest-port" notation is hopefully clear
enough). We will call a
connection-tracking entry a "CTE" from now on.
LVS notices (in ip_vs_in(), called as part of the LOCAL_INPUT hook) that
VIP:VPORT is something it's interested in, grabs the packet, re-writes it to
be addressed
CIP:CPORT -> RIP:RPORT
and sends it on its way by means of ip_send(). As a result, the
POST_ROUTING
hook gets called, and ip_vs_post_routing() gets a look at the packet. It
notices that the packet has been marked as belonging to LVS, and calls the
(*okfn), sending the packet to the wire without further ado.
When it has been transmitted, the reference count on the CTE falls to zero,
and it is deleted. (This is a mild guess but I think is right.) Normally,
CTEs avoid this fate because __ip_conntrack_confirm() is called for them,
either via ip_confirm() as a late hook in LOCAL_IN, or through ip_refrag()
called as a late hook in POST_ROUTING. "Confirming" the CTE involves
linking
it into some hash tables, and ensuring it isn't deleted.
So this is the first problem --- the CTE is not "confirmed".
Suppose we confirmed the connection. Then when the Real Server replies to
this packet, it sends a packet addressed as
RIP:RPORT -> CIP:CPORT
to the director (because the Director is the router for such packets, as
seen by the Real Server). Then the connection-tracking code in Netfilter on
the director tries to look up the CTE for this packet, but can't find one.
The CTE we /want/ it to match says
ORIG: CIP:CPORT -> VIP:VPORT
REPL: VIP:VPORT -> CIP:CPORT
with no mention of the RIP:RPORT. So this reply packet gets labelled as
"NEW", whereas we wanted it to be labelled as "ESTABLISHED".
So as well as confirming the CTE, we also need to alter the REPLY tuple so
that it will match the
RIP:RPORT -> CIP:CPORT
packet the Real Server sends back. Then everything will work.
These two things are what the ip_vs_deal_with_conntrack() function does.
Luckily there is a ip_conntrack_alter_reply() function exported by
Netfilter, which we can use. Then we can also call the newly-exported
__ip_conntrack_confirm() to confirm the connection. (We need to do the
reply
altering first because __ip_conntrack_confirm()ing the CTE uses the
addresses in the ORIG and REPLY tuples to place the CTE in the hash tables,
and we want it placed based on the /new/ reply tuple.)
There is a slight complication in that the NAT code in Netfilter gets
confused if addressing tuples change, so we need to tell the NAT code to re
-place the CTE in its hash tables. This is done with the newly-exported
ip_nat_replace_in_hashes() function.
The ip_vs_deal_with_conntrack() function is called from the
ip_vs_nat_xmit()
function, since this whole problem only applies to LVS-NAT. It is only
called if the CTE is unconfirmed.
Hacking round a possible race
When testing this, we found that very occasionally there would be a problem
when the Netfilter CTE timed out and was deleted. The code would fail an
assertion: the CTE about to be deleted was not linked into the hash chain it
claimed it was. This would happen after a few tens of thousands of
connections from the same client to the same virtual service.
We tracked this down to the above ip_vs_deal_with_conntrack() code being
called for a CTE which already existed and was already confirmed. Doing this
moved the CTE to a different hash chain and broke things.
The only explanation I could come up with is that there is a race in the
ip_vs code. The ip_vs code doesn't set up one timer per connection entry.
Instead, it uses a kernel timer to do some work every second. I didn't look
into this too deeply, but it looked like the following is a possibility.
If the slow-timer code decides that a LVS connection should be expired,
there seems to be a window where a packet can arrive and update that
connection, meaning that it should no longer be expired. But it is anyway.
There are more details; supplied on request. But if somebody who knows the
timer code could check whether the above is a possibility, and fix it if so,
that would be good.
The workaround detects if the CTE is already confirmed, and deletes it and
also drops the packet if so. Higher levels in the stack take care of
retransmitting so nothing too drastic goes wrong.
Later, we noticed the workaround being triggered much more often than we'd
expect, and it turned out that incoming packets with the SYN and ACK bits
both set were being treated as potentially starting new connections,
whereas
SYN/ACK packets are in fact a response to a connection initiated by the
director itself. So we tightened the test to be
((h.th->syn && !h.th->ack) || (iph->protocol != IPPROTO_TCP))
instead of
(h.th->syn || (iph->protocol!=IPPROTO_TCP))
which is how it is in the original LVS code. This doesn't seem to have
caused any nasty side effects.
Note that this only happened when an FTP virtual service was configured,
because of the code in ip_vs_service_get() which allows a "wild-card" match
for incoming FTP data connections.
29.9.3.2. FTP connections
The other main change is to the LVS FTP module. We add code to the two
functions ip_vs_ftp_out() and ip_vs_ftp_in(), to deal with passive and
active data transfers respectively. The basic idea is the same for both
types of transfer.
By keeping an eye on the actual traffic going between the client and the FTP
server, we can tell when a data transfer is about to take place. For a
passive transfer, the ip_vs_ftp module looks out for the string "227
Entering Passive Mode" followed by the address and port the server will
listen on. For an active transfer, the client transmits the "PORT" command
followed by the address and port the client will listen on.
Once we have detected that a data transfer is about to take place, we add
code to tell Netfilter's connection-tracking code to /expect/ the data
connection. Then, packets belonging to the data connection will be labelled
"RELATED" and can be allowed by firewall rules. There is an exported
function ip_conntrack_expect_related(), which we call. The only difference
between the set-up for passive and active transfers is that for passive
transfers we don't know the port the client will connect from, so have to
specify the source port as "don't care" by means of its mask.
The ip_conntrack_expect_related() function allows us to specify a callback
function; we use ip_vs_ftp_expect_callback() (new function in this patch).
ip_vs_ftp_expect_callback() works out whether the new connection is for
passive or active, modifies the REPLY tuple, and confirms the CTE.
I've just noticed that I modify the reply tuple directly instead of calling
ip_conntrack_alter_reply(). Can't see any good reason for this, so should
probably change the code to use ip_conntrack_alter_reply() instead. Might
not have time to test that change here, so will leave it alone for now.
So to run a virtual FTP service, load the extra ip_vs_ftp module, but /not/
the ip_conntrack_ftp or ip_nat_ftp modules. It is very likely that the
ip_vs_ftp module would not cooperate very well with those two modules, so if
you want to run a non-virtual FTP service /and/ load-balance a virtual FTP
service on the same machine, more work might be required.
route_me_harder()
We call this function to possibly re-route the packet, because we were using
policy routing (iproute2). This allows routing decisions to depend on more
than just the destination IP address of the packet. In particular, a routing
decision can be influenced by the source IP address of the packet, and by
the fact that the packet should be treated as originating with the local
machine. The call to route_me_harder() re-makes the routing decision in
light of the new state of the packet. It could be removed (or disabled via a
sysctl) if the overhead was too annoying in an application which didn't
require this extra flexibility.
Additional #defines
There are additional #defines available to add assertion-checking and
various amounts of debugging to the output of the new code.
#define BN_ASSERTIONS to include extra code which checks various things are
as they should be. This adds a small amount of overhead (sorry, haven't
measured it) but caught some problems in development.
#define BN_DEBUG_FTP to emit diagnostic and tracing information from the
modified ip_vs_ftp module. Again, was useful during development but probably
not useful in production.
#define BN_DEBUG_IPVS_CONN to emit diagnostic and tracing information from
the new code which handles Netfilter's CTEs. Same comments apply: useful
while I was working on it, but probably not in actual use.
29.10. The design of LVS as a netfilter module, pt1
Tao Zhao taozhao (at) cs (dot) nyu (dot) edu 11 Jul 2001
The source code of LVS adds ip_vs_in() to netfilter hook NF_IP_LOCAL_IN
to change the destination of packets. As I understand, this hook is called
AFTER routing decisions have reached. So how can it forward the packet to
the new assigned destination without routing?
Henrik Nordstrom hno (at) marasystems (dot) com
Instead of rewriting the packet inside the normal packet flow of Linux-2.4,
IPVS accepts the packet and constructs a new one, routes it and sends it
out.. This approach does not make much sense for LVS-NAT within the
netfilter framework, but fits quite well for the other modes.
Julian
LVS does not follow the netfilter recommendations. What happens if we don't
change the destination (e.g.DR and TUN methods which don't change the IP
header). When such packet hits the routing the IP header fields are used for
the routing decision. Netfilter can forward only by using NAT methods.
LVS tries not to waste CPU cycles in the routing cache. You can see that
there is output routing call involved but there is a optimization you can
find even in TCP - the destination cache. The output routing call is avoided
in most of the cases. This model is near the one achieved in Netfilter, i.e.
to call only once the input routing function (2.2 calls it twice for DNAT).
I'm now testing a patch for 2.2 (on top of LVS) that avoids the second input
routing call and that can reroute the masqueraded traffic to the right
gateway when many gateways are used and mostly when these gateways are on
same device. The tests will show how different is the speed between this
patched LVS for 2.2 and the 2.4 one (one CPU of course).
We decided to use the LOCAL_IN hook for many reasons. May be you can find
more info for the LVS integration into the Netfilter framework by searching
in the LVS mail list archive for "netfilter".
Julian 29 Oct 2001
IPVS uses only the netfilter's hooks. It uses own connection tracking and
NAT. You can see how LVS fits into the framework on the mailing list
archive.
Ratz
I see that the defense_level is triggered via a sysctrl and invoked in
the sltimer_handler as well as the *_dropentry. If we push those functions
on level higher and introduce a metalayer that registers the defense_strategy
which would be selectable via sysctrl and would currently
contain update_defense_level we had the possibility to register other
defense strategies like e.g. limiting threshold. Is this feasible? I mean
instead of calling update_defense_level() and ip_vs_random_dropentry() in
the sltimer_handler we just call the registered defe
nse_strategy[sysctrl_read] function. In the existing case the
defense_strategy[0]=update_defense_level() which also merges the
ip_vs_dropentry. Do I make myself sound stupid? ;)
The different strategies work in different places and it is difficult to use
one hook. The current implementation allows they to work together. But may
be there is another solution considering how LVS is called: to drop packets
or to drop entries. There are no many places for such hooks, so may be it is
possible something to be done. But first let's see what kind of other
defense strategies will come.
Yes, the project got larger and more reputation than some of us
initially thought. The code is very clear and stable, it's time to enhance
it. The only very big problem that I see is that it looks like we're going
to have to separate code paths one patch for 2.2.x kernels and one for
2.4.x.
Yes, this is the reality. We can try to keep the things not to look different
for the user space.
This would be a pain in the ass if we had two versions of ipvsadm. IMHO
the userspace tools should recognize (compile-time) what kernel it is
working with and therefore enable the featureset. This will of course bloat
it up in future the more feature-differences we will have regarding 2.2.x
and 2.4.x series.
Not possible, the sockopt are different in 2.4
Joe (I think)
Could you point me to a sketch where I could try to see how the control
path for a packet looks like in kernel 2.4? I mean some- thing like I would
do for 2.2.x kernels:
Julian (I think)
I hope there is a nice ascii diagram in the netfilter docs, but I hope the
info below is more useful if you already know what each hook means.
----------------------------------------------------------------
| ACCEPT/ lo interface |
v REDIRECT _______ |
--> C --> S --> ______ --> D --> ~~~~~~~~ -->|forward|----> _______ -->
h a |input | e {Routing } |Chain | |output |ACCEPT
e n |Chain | m {Decision} |_______| --->|Chain |
c i |______| a ~~~~~~~~ | | ->|_______|
k t | s | | | | |
s y | q | v | | |
u | v e v DENY/ | | v
m | DENY/ r Local Process REJECT | | DENY/
| v REJECT a | | | REJECT
| DENY d --------------------- |
v e -----------------------------
DENY
Ratz (I think)
The biggest problem I see here is that maybe the user space daemons
don't get enough scheduling time to be accurate enough.
That is definitely true. When the CPU(s) are busy transferring packets the
processes can be delayed. So, the director better not spend many cycles in
user space. This is the reason I prefer all these health checks to run in
the realservers but this is not always good/possible.
No, considering the fact that not all RS are running Linux. We would
need to port the healthchecks to every possible RS architecture.
Yes, this is a drawback.
unknown (Ratz ?)
Tell me, which scheduler should I take? None of the existing ones gives
me good enough results currently with persistency. We have to accept the
fact, that 3-Tier application programmers don't know about loadbalancing or
clustering, mostly using Java and this is just about the end of trying to
load balance the application smoothly.
WRR + load informed cluster software. But I'm not sure in the the case when
persistency is on (it can do bad things).
I currently get some values via an daemon coded in perl on the RS,
started via xinetd. The LB connects to the healthcheck port and gets some
prepared results. He then puts this stuff into a db and starts calculating
the next steps to reconfigure the LVS-cluster to smoothen the imbalance.
The
longer you let it running the more data you get and the less adjustments
you
have to make. I reckon some guy showing up on this list once had this idea
in direction of fuzzy logic. Hey Julian, maybe we should accept the fact
that the wlc scheduler also isn't a very advanced one:
loh = atomic_read(&least->activeconns)*50+atomic_read(&least->inactconns);
What would you think would change if we made this 50 dynamic?
Not sure :) I don't have results from experiments with wlc :) You can put it
in /proc and to make different experiments, for example :) But warning,
ip_vs_wlc can be module, check how lblc* register /proc vars.
29.11. The design of LVS for Netfilter and Linux 2.4, pt2
The most recent version of Julian's writeup of LVS and Netfilter (NF) is on
the LVS website. Here is the version available in Jun 2002.
29.11.1. TODO:
- redesign LVS to work in setups with multiple default routes (this requires
changes in the kernels, calling ip_route_input with different arguments).
The end goal: one routing call in any direction (as before) but do correct
routing in in->out direction. The problems:
- fwmark virtual services and the need for working at prerouting.
Solution: hook at PREROUTING after the filter and do there connection
creation (after QoS, fwmark setup). Hook at prerouting, listen for traffic
for established connections and call ip_route_input with the right arguments
(possibly in the routing chain). Goal: always pass one filter chain in each
direction (FORWARD). The fwmark is used only for connection setup and then is ignored.
- hash twice the NAT connections in same table (at prerouting we can see
both requests and replies), compare with cp->vaddr to detect the right direction
- help from Netfilter to redesign the kernel hooks:
- ROUTING hook (used from netfilter's NAT, LVS-DR and in->out LVS-NAT)
- fixed ip_route_input to do source routing with the masquerade address as
source (lsrc argument)
- more control over what to walk in the netfilter hooks?
- different timeouts for each virtual server (more control over the connection timeouts)
- Allow LVS to be used as NAT router/balancer for outgoing traffic
29.11.2. CURRENT STATE:
Running variants:
1. Only lvs - the fastest
2. lvs + ipfw NAT
3. lvs + iptables NAT
Where is LVS placed:
LOCAL_IN:100 ip_vs_in
FORWARD:99 ip_vs_forward_icmp
FORWARD:100 ip_vs_out
POST_ROUTING:NF_IP_PRI_NAT_SRC-1 ip_vs_post_routing
The chains:
The out->in LVS packets (for any forwarding method) walk:
pre_routing -> LOCAL_IN -> ip_route_output or dst cache -> POST_ROUTING
LOCAL_IN
ip_vs_in -> ip_route_output/dst cache
-> mark skb->nfcache with special bit value
-> ip_send -> POST_ROUTING
POST_ROUTING
ip_vs_post_routing
- check skb->nfcache and exit from the
chain if our bit is set
The in->out LVS packets (for LVS/NAT) walk:
pre_routing -> FORWARD -> POST_ROUTING
FORWARD (check for related ICMP):
ip_vs_forward_icmp -> local delivery -> mark
skb->nfcache -> POST_ROUTING
FORWARD
ip_vs_out -> NAT -> mark skb->nfcache -> NF_ACCEPT
POST_ROUTING
ip_vs_post_routing
- check skb->nfcache and exit from the
chain if our bit is set
Why LVS is placed there:
- LVS creates connections after the packets are marked, i.e. after
PRE_ROUTING:MANGLE:-150 or PRE_ROUTING:FILTER:0. LVS can use the skb->nfmark
as a virtual service ID.
- LVS must be after PRE_ROUTING:FILTER+1:sch_ingress.c - QoS setups. By this
way the incoming traffic can be policed before reaching LVS.
- LVS creates connections after the input routing because the routing can
decide to deliver locally packets that are marked or other packets specified
with routing rules. Transparent proxying handled from the netfilter NAT code
is not always a good solution.
- LVS needs to forward packets not looking in the IP header (direct routing
method), so calling ip_route_input with arguments from the IP header only is
not useful for LVS
- LVS is after any firewall rules in LOCAL_IN and FORWARD
29.11.3. Requirements for the PRE_ROUTING chain
Sorry, we can't waste time here. The netfilter connection tracking can
mangle packets here and we don't know at this time if a packet is for our
virtual service (new connection) or for existing connection (needs lookup in
the LVS connection table). We are sure that we can't make decisions whether
to create new connections at this place but lookup for existing connections
is possible under some conditions: the packets must be defragmented, etc.
There are so many nice modules in this chain that can feed LVS with packets
(probably modified)
29.11.4. Requirements for the LOCAL_IN chain
The conditions when sk_buff comes:
- ip_local_deliver() defragments the packets (ip_defrag) for us
- the incoming sk_buff can be non-linear
- when the incoming sk_buff comes only the read access is guaranteed
What we do:
- packets generated locally are not considered because there is no known
forwarding method that can establish connection initiated from the
director.
- only TCP, UDP and related to them ICMP packets are considered
- the protocol header must be present before making any work based on fields
from the IP or protocol header.
- we detect here packets for the virtual services or packets for existing
connections and then the transmitter function for the used forwarding method
is called
- the NAT transmitter performs the following actions:
We try to make some optimizations for the most of the traffic we see:
the normal traffic that is not bound to any application helper, i.e. when
the data part (payload) in the packets is not written or even not read at
all. In such case, we change the addresses and the ports in the IP and in
the protocol header but we don't make any checksum checking for them. We
perform incremental checksum update after the packet is mangled and rely on
the realserver to perform the full check (headers and payload).
If the connection is bound to some application helper (FTP for example)
we always perform checksum checking with the assumption that the data is
usually changed and with the additional assumption that the traffic using
application helpers is low. To perform such check the whole payload should
be present in the provided sk_buff. For this, we call functions to linearize
the sk_buff data by assembling all its data fragments.
Before the addresses and ports are changed we should have write access
to the packet data (headers and payload). This guarantees that the packet
data should be seen from any other readers unchanged. The copy-on-write is
performed from the linearization function for the packets that were with
many fragments. For all other packets we should copy the packet data
(headers and payload) if it is used from someone else (the sk_buff was
cloned). The packets not bound to application helpers need such write access
only for the first fragment because for them only the IP and the protocol
headers are changed and we guarantee that they are in the first fragment.
For the packets using application helpers the linearization is already done
and we are sure that there is only one fragment. As result, we need write
access (copy if cloned) only for the first fragment. After the application
helper is called to update the packet data we perform full checksum
calculation.
- the DR transmitter performs the following actions:
Nothing special, may be it is the shortest function. The only action is
to reroute the packet to the bound realserver. If the packet is fragmented
then ip_send_check() should be called to refresh the checksum.
- the TUN transmitter performs the following actions:
Copies the packet if is already referred from someone else or when there
is no space for the IPIP prefix header. The packet is rerouted to the real
server. If the packet is fragmented then ip_send_check() should be called to
refresh the checksum in the old IP header.
- if the packets must leave the box we send them to POST_ROUTING via ip_send
and return NF_STOLEN. This means that we remove the packet from the LOCAL_IN
chain before reaching priority LAST-1. The LocalNode feature just returns
NF_ACCEPT without mangling the packet.
In this chain if a packet is for LVS connection (even newly created) the
LVS calls ip_route_output (or uses a destination cache), marks the packet as
a LVS property (sets bit in skb->nfcache) and calls ip_send() to jump to the
POST_ROUTING chain. There our ip_vs_post_routing hook must call the okfn for
the packets with our special nfcache bit value (Is skb->nfcache used after
the routing calls? We rely on the fact that it is not used) and to return
NF_STOLEN.
One side effect: LVS can forward packet even when ip_forward=0, only for
DR and TUN methods. For these methods even TTL is not decremented nor data
checksum is checked.
29.11.5. Requirements for the FORWARD chain
LVS checks first for ICMP packets related to TCP or UDP connections. Such
packets are handled as they are received in the LOCAL_IN chain - they are
localy delivered. Used for transparent proxy setups.
LVS looks in this chain for in->out packets but only for the LVS/NAT method.
In any case new connections are not created here, the lookup is for existing
connections only.
In this chain the ip_vs_out function can be called from many places:
FORWARD:0 - the ipfw compat mode calls ip_vs_out between the forward
firewall and the masquerading. By this way LVS can grab the outgoing packets
for its connection and to avoid they to be used from the netfilter's NAT
code.
FORWARD:100 - ip_vs_out is registered after the FILTER=0. We can come here
twice if the ipfw compat module is used because ip_vs_out is called once
from FORWARD:0 (fw_in) and after that from pri=100 where LVS always
registers the ip_vs_out function. We detect this second call by looking in
the skb->nfcache bit value. If the bit is set we return NF_ACCEPT. In fact,
the second ip_vs_out call is avoided if the first returns NF_STOLEN and
after calling the okfn function.
The actions we perform are the same as in the LOCAL_IN chain for the NAT
transmitter with the exception that we should call ip_defrag(). The other
difference is that we have write access to the first fragment (it is not
referred from someone else) after ip_forward() calls skb_cow().
29.11.6. Requirements for the POST_ROUTING chain
LVS marks the packets for debugging and they appear to come from LOCAL_OUT
but this chain is not traversed. The LVS requirements from the POST_ROUTING
chain include the fragmentation code only. But even the ICMP messages are
generated and mangled ready for sending long before the POST_ROUTING chain:
ip_send() does not call ip_fragment() for the LVS packets because LVS
returns ICMP_FRAG_NEEDED when the mtu is shorter.
LVS makes MTU checks when accepting packets and selecting the output device.
So, the ip_refrag POST_ROUTING hook is not used from LVS.
The result is: LVS must hook POST_ROUTING as first (may be only after the
ipfw compat filter) and to return NF_STOLEN for its packets (detected by
checking the special skb->nfcache bit value).
The Netfilter hooks:
Priorities:
NF_IP_PRI_FIRST = INT_MIN,
NF_IP_PRI_CONNTRACK = -200,
NF_IP_PRI_MANGLE = -150,
NF_IP_PRI_NAT_DST = -100,
NF_IP_PRI_FILTER = 0,
NF_IP_PRI_NAT_SRC = 100,
NF_IP_PRI_LAST = INT_MAX,
PRE_ROUTING (ip_input.c:ip_rcv):
CONNTRACK=-200, ip_conntrack_core.c:ip_conntrack_in
MANGLE=-150, iptable_mangle.c:ipt_hook
NAT_DST=-100, ip_nat_standalone.c:ip_nat_fn
FILTER=0, ip_fw_compat.c:fw_in, defrag, firewall, demasq, redirect
FILTER+1=1, net/sched/sch_ingress.c:ing_hook
LOCAL_IN (ip_input.c:ip_local_deliver):
FILTER=0, iptable_filter.c:ipt_hook
LVS=100, ip_vs_in
LAST-1, ip_fw_compat.c:fw_confirm
CONNTRACK=LAST-1, ip_conntrack_standalone.c:ip_confirm
FORWARD (ip_forward.c:ip_forward):
FILTER=0, iptable_filter.c:ipt_hook
FILTER=0, ip_fw_compat.c:fw_in, firewall, LVS:check_for_ip_vs_out,
masquerade
LVS=99, ip_vs_forward_icmp
LVS=100, ip_vs_out
LOCAL_OUT (ip_output.c):
CONNTRACK=-200, ip_conntrack_standalone.c:ip_conntrack_local
MANGLE=-150, iptable_mangle.c:ipt_local_out_hook
NAT_DST=-100, ip_nat_standalone.c:ip_nat_local_fn
FILTER=0, iptable_filter.c:ipt_local_out_hook
POST_ROUTING (ip_output.c:ip_finish_output):
FILTER=0, ip_fw_compat.c:fw_in, firewall, unredirect,
mangle ICMP replies
LVS=NAT_SRC-1, ip_vs_post_routing
NAT_SRC=100, ip_nat_standalone.c:ip_nat_out
CONNTRACK=LAST, ip_conntrack_standalone.c:ip_refrag
CONNTRACK:
PRE_ROUTING, LOCAL_IN, LOCAL_OUT, POST_ROUTING
FILTER:
LOCAL_IN, FORWARD, LOCAL_OUT
MANGLE:
PRE_ROUTING, LOCAL_OUT
NAT:
PRE_ROUTING, LOCAL_OUT, POST_ROUTING
29.12. Example ip_tables filter scripts
A simple firewall installation script is gshield.
This script below by Tim Cronin, was written before ipvs netfilter
connection tracking module, ipvs_nfct became available.
Tim Cronin tim (at) 13-colonies (dot) com 14 Feb 2003
# ipvsadm
IP Virtual Server version 1.0.6 (size=1048576)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP xx.xx.xx.xx:http wlc persistent 1200
-> 192.168.1.25:http Masq 1 0 2
TCP xx.xx.xx.xx:http wlc persistent 1200
-> 192.168.1.20:http Masq 2 16 11
-> 192.168.1.10:http Masq 3 17 23
This script (http://www.austintek.com/LVS/LVS-HOWTO/
HOWTO/files/tim_cronin.sh) has been running reliably in production for 6
months. The link at the top of the script is a good starting point to
understand how it works. Note that the default config generates copious
logs. The IP addresses have been changed to protect the innocent server. I
had problems with the syn flag hence the section ignoring stuff going to the vips.
29.13. performance hit on director with iptables/netfilter
Dant dan (at) id-confirm (dot) com
I setup an intrusion detection system (IDS) on the director, and I had a simple
test on the director by connectting the mean-service-time, HitRatio .. which
cost me dual weeks. And I found that snort does not affect the performance.
ratz 16 Nov 2005
Depends on the configuration, it's actually quiet easy to kill Snort with
some advanced ruleset and above L4 checks.
as both snort and iptables use libpcap library to scratch packets,
iptables does not use libpcap, to my avail, so I'm not sure I understand
your question.
does it mean the iptables will not affect the director's performance ?
or am I right before when using snort?
iptables is the user space part of netfilter, which is in the kernel. So no,
iptables will not hurt performance, but netfilter certainly does, depending
on the usage, amount of rules and your hardware configuration.
I'm running several highly loaded LVSs, these days I found that there
are so many malicious scans, so I want to ban them all by portsentry. And we
also confused by by ddos :-/
Portsentry only mitigates the problem, doesn't solve it. Also, it's not
something that should be implemented on the LVS. Also having a NIDS on the
director is a bit suboptimal, since a IDS should at best not be detectable
and should also be in read-only mode. Either put a second box between the
networks you need to sniff, preferrably in bridge mode or modify your
network cables by removing the TX part, so only receiving is possible. Both
suggestions don't work well with a director.
On the modifying-network-cables-for-IDS part: http:/
/www.snort.org/docs/tap/
While we're touching on this subject here, what kind of a NIDS do people
use inside an LVS setup, and how can it be implemented?
There's nothing special about LVS that would require a different approach to
NIDS, so this is more a general question off how to deploy IDS; and this,
I'm afraid, is subject to personal views. I don't know on which
level you plan on deploying IDS, but a good starter is the Snort
documentation corner, which can be found at: http://www.snort.org/docs/
Especially interesting is the IDS load balancer. I've talked to Marty about
load balancing traffic to multiple IDS nodes to share the load in 2001 I
think, however I don't remember what our consensus was.
Other than that you'd have to be a bit more specific. I'd be glad to help,
although I've left the IDS field 2-3 years ago. One of the reason is that
with the Basel II and the Sarbanes-Oxley acts (http:
//www.aicpa.org/sarbanes/index.asp) you barely can't allow yourself anymore
to "lose" data, which in the sense of IDS translates to either "false
positives" or "true negatives". Since the two items mentioned are a general
issue of IDS systems, that require highly skilled personnel, other means to
acquire the demanded level of security quality management have to be found,
for example: reliable logging and monitoring, on top of a well-thought and
implemented security policy.
29.14. Long sessions through LVS DR director terminated by icmp-host
-prohibited (ICMP type 3 code 10)
Note
This problem was found in the normal operation of an LVS. The problem is
with netfilter, not LVS. Netfilter is gratuitously sending icmp packets in
an ESTABLISHED connection. We don't know what the problem is about (yet).
It's here in case someone else finds it too.
Klaas Jan Wierenga k (dot) j (dot) wierenga (at) home (dot) nl 13 Mar 2007
I have a problem where sometimes some long standing mp3 streaming sessions
over HTTP are terminated because the LVS-DR director sends an "ICMP type 3
code 10 - host unreachable" packet to the client (which is the source of the
mp3 stream). When this happens the client stops sending packets for 15
minutes 15 minutes (the TCP idle session timeout of LVS?) before it
reconnects on the same ports. The 15 minutes seems to be related to the
connection timing out of the LVS connection table.
When this happens the real servers are all fine, load is not heavy and
ldirectord is able to perform it's checks. In fact nothing shows in the
ldirectord.log so the real servers are all available. This is quite a long
post, I've tried to include all relevant details.
My setup: ISP router -> LVS Director -> Local switch -> Realserver[123] -> ISP router
Directions I've looked into so far and questions I've asked myself:
- enabled "quiescent=yes" to maybe not terminate existing connection, but
this is not the problem I think because the real servers are all available
when this happens.
- Where is this ICMP packet generated in linux/net/ipv4/ipvs/* source
files? Answer: nowhere!, at least not with type 3 code 10
- Could it be that this ICMP packet is generated by some sort of denial
-of
-service defense code that I'm unaware of?
- Where is this specific ICMP packet (HOST_UNREACH_ANO) genererated in the
kernel?
Answer: net/ipv4/netfilter/ipt_REJECT.c: send_unreach(*pskb, ICMP_HOST_ANO);
So it appears that netfilter (iptables?) is sending it. Why? This could
be due to the firewall rule:
REJECT all -- anywhere anywhere reject -with icmp-host-prohibited
But why is this sent on an existing, established and active connection?
Or is there some TCP timeout because the director only sees incoming packets
on the connection? Maybe this rings a bell with someone.
- Maybe the client is not behaving correctly by not continuing to send
data after receiving ICMP host unreachable? TCP/IP Illustrated Vol1
[Stevens] says on page 317, 21.10 ICMP Errors:
"A received host unreachable or network unreachable is effectively
ignored, since these two errors are considered transient. ... It could be
that an intermediate router has gone down and it can take the routing
protocols a few minutes to stabilize on an alternative route.. During this
period either of these two ICMP errors can occur, but the must not abort the
connection. Instead, TCP keeps trying to send the data that caused the
error, although it may eventually time out."
Later...
A while ago I posted about a problem I was having with long mp3 streaming
sessions which were terminated because the streaming LVS cluster (managed by
me) was sending icmp-host-prohibited on an established connection to the
client which was causing the connection to be terminated.
Initially I suspected the LVS director but after some investigation I found
out that it never sends icmp-host-prohibited. The only other possibility was
netfilter sending it. The relevant parts of my initial iptables was
(/etc/sysconfig/iptables):
*filter
:FORWARD ACCEPT [0:0]
:INPUT ACCEPT [0:0]
:RH-Firewall-1-INPUT - [0:0]
:OUTPUT ACCEPT [0:0]
-A FORWARD -j RH-Firewall-1-INPUT
-A INPUT -j RH-Firewall-1-INPUT
-A RH-Firewall-1-INPUT -i lo -j ACCEPT
-A RH-Firewall-1-INPUT -p icmp -m icmp --icmp-type any -j ACCEPT
-A RH-Firewall-1-INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT
-A RH-Firewall-1-INPUT -p tcp -m state -m tcp --dport 80 --state NEW -j ACCEPT
-A RH-Firewall-1-INPUT -j REJECT --reject-with icmp-host-prohibited
COMMIT
After I changed the port 80 rule to the one below effectively disabling
connection tracking on port 80 the problem disappeared.
-A RH-Firewall-1-INPUT -p tcp --dport 80 -j ACCEPT
Initially I made this iptables change on the LVS director, but then the
realservers would send icmp-host-prohibited sometimes on established connections
, after also changing iptables on the realservers did the problem go away.
It is still unclear to me why netfilter would decide to send icmp-host
-unreachable on established connection when connection tracking is active.
Maybe someone on the netfilter list can shed some light on this.
Still later... did you ever find a better solution?
Klaas Jan Wierenga k (dot) j (dot) wierenga (at) home (dot) nl 26 Jun 2007
Not really. It appears to be a netfilter problem because when I changed my
firewall rules (/etc/sysconfig/iptables) to disable connection tracking, the
problem went away.
# Don't do connection tracking on port 80 and 8000,
# because sometimes it results in dropped connections due to
ICMP_HOST_UNREACHABLE messages
#
#-A RH-Firewall-1-INPUT -p tcp -m state -m tcp --dport 80 --state NEW -j ACCEPT
#-A RH-Firewall-1-INPUT -p tcp -m state -m tcp --dport 8000 --state NEW -j ACCEPT
-A RH-Firewall-1-INPUT -p tcp --dport 80 -j ACCEPT
-A RH-Firewall-1-INPUT -p tcp --dport 8000 -j ACCEPT
29.15. stateful filtering: LVS-NAT
Note
Laurentiu didn't know about Siim Poder's patch for stateful LVS-NAT
filtering about 2 months previously FIXME: write up Siim's patch and link
this to it.
Laurentiu C. Badea (L.C.) lc (at) waat (dot) com 10 Sep 2008
This is my solution to the problem I found of the last FIN-ACK eaten by
iptables. I had a simple LVS-NAT configuration where LVS lives on a gateway:
The kernel is 2.6.20 with ipvsadm 1.24 (Fedora 5).
CIP - VIP/LVS - RIP
LVS does run iptables but fairly open, INPUT allows all incoming traffic for
the VIP, OUTPUT allows NEW,ESTABLISHED,RELATED states and FORWARD is open
(for what it's worth, I think ipvs does not go through there at all). So that
worked fine.
Until I noticed the real server has many connections in FIN_WAIT2 state.
They have the same timeout as TIME_WAIT so I was gonna let it go, but then I
looked at the client and all of them were in LAST_ACK state. The client kept
resending FIN-ACKs, none of which made it to the server at all. On the LVS,
ipvsadm -Lc shows connections in TIME_WAIT state so it did get them.
Well, long story short, the OUTPUT chain blocked *only* that FIN-ACK packet
for some odd reason. I was sure that ipvs is shortcircuiting iptables and
bypassing OUTPUT, but I guess I misinterpreted the little map in the HOWTO.
All the other packets matched the "NEW" rule. This would would have ended up
as INVALID probably. I am now adding rules to allow all OUTPUT towards the
RIPs, stateless.
This is how it looked from the network side:
Incoming traffic to LVS (CIP->VIP)
0.016862 CIP -> VIP HTTP HEAD / HTTP/1.1
0.017193 VIP -> CIP [ACK] Seq=1 Ack=117 Win=5888 Len=0
0.021949 VIP -> CIP [TCP segment of a reassembled PDU]
0.022173 VIP -> CIP [FIN, ACK] Seq=195 Ack=117 Win=5888 Len=0
0.034046 CIP -> VIP [ACK] Seq=117 Ack=195 Win=6912 Len=0
*0.046042 CIP -> VIP [FIN, ACK] Seq=117 Ack=196 Win=6912 Len=0*
the above packet does not make it, beyond here retransmits only
0.250217 VIP -> CIP [FIN, ACK] Seq=195 Ack=117 Win=5888 Len=0
0.260110 CIP -> VIP [FIN, ACK] Seq=117 Ack=196 Win=6912 Len=0
0.267333 CIP -> VIP [TCP Dup ACK 11#1] [ACK] Seq=118 Ack=196 Win=6912 Len=0 SLE=195 SRE=196
0.705855 CIP -> VIP [FIN, ACK] Seq=117 Ack=196 Win=6912 Len=0
Coming out the other end towards RIP:
0.016847 CIP -> RIP HTTP HEAD / HTTP/1.1
0.017119 RIP -> CIP [ACK] Seq=1 Ack=117 Win=5888 Len=0
0.021873 RIP -> CIP [TCP segment of a reassembled PDU]
0.022115 RIP -> CIP [FIN, ACK] Seq=195 Ack=117 Win=5888 Len=0
0.034021 CIP -> RIP [ACK] Seq=117 Ack=195 Win=6912 Len=0
only two retransmits seen:
0.250147 RIP -> CIP [FIN, ACK] Seq=195 Ack=117 Win=5888 Len=0
0.267312 CIP -> RIP [TCP Previous segment lost] [ACK] Seq=118 Ack=196
Win=6912 Len=0 SLE=195 SRE=196
The current setup seems to work except for a minor annoyance - the netfilter
conntrack table still has the connections, when I would have expected that
to be almost empty, given that LVS steals the packets from nf. The
connections display as UNREPLIED and originating on the RIP:80 so they
aren't "real" but I'm curious which packets from the real server triggered them.
A blanket ACCEPT rule on outgoing traffic doesn't seem very secure for a
firewall, and in my case there's a firewall in front of the LVS.
Outgoing FORWARDed traffic is not the one allowed though, it is the traffic
originating on the LVS machine itself, the OUTPUT chain in the main table
which is usually left open anyway.
Since then I have noticed the INPUT chain would have blocked the same packet
in the same configuration, so both INPUT and OUTPUT need to have a stateless
ACCEPT on that tcp port for the LVS to work.
29.16. stateful filtering: LVS-DR
Note
Because the director cannot see the reply packets from the realserver, the
standard netfilter stateful filtering can't be used with LVS-DR (or LVS -Tun).
Thomas Pedoussaut thomas (at) pedoussaut (dot) com 22 Apr 2008
For one of my dozen of services ( a straight TCP connection), the TCP-FIN
packets that are arriving on the load balancer are never passed to the real
server. I activated the logs of iptable and could see the FIN packets being
dropped. No idea why the FIN are dropped and not the other ones. I obviously
have the --state ESTABLISHED,RELATED -j ACCEPT in my iptable rules.
I had a quick look at /proc/net/ip_conntrack before, during and after the
connection but nothing specific to that connection seems to be inserted (the
module is loaded and other traffic gets tracked).
It even happen when I close the client connection within seconds of
creation, so I don't think timeouts are involved. My issue is that the
application in backend doesn't deal with timeouts, so never initiate the
closing of the connection.
Later...
Basically, all packets (SYN and non-SYN) are allowed by the "--state NEW"
iptables but not by the ESTABLISHED,RELATED, because the director never sees
the replies from the real server and so never creates a conntrack for that
connection. When a FIN packet arrives, it is not validated as a --state NEW,
because it's flag FIN is activated and so, that particular packet is
dropped.
So the solution is to change the iptables rule
from
-A RH-Firewall-1-INPUT -m state --state NEW -m tcp -p tcp --dport $VPORT -j ACCEPT
to
-A RH-Firewall-1-INPUT -m tcp -p tcp --dport $VPORT -j ACCEPT